一个输入法明文 HTTP 传输用户隐私的漏洞事实,还有一个事关用户隐私的猜想。两者之间是否有关联?本文复现了视频中的抓包实验,但得出了不一样的结论。
注意时效性:本文使用三星输入法 5.6.00.48 版本于 2024 年 1 月 25 日进行测试,仅代表该软件在该软件版本、该时刻下的行为。因此本文具备高度时效性,另外,本文所述的分析也可能并不完备,请谨慎鉴别。
一个漏洞与一个猜想
在视频《某品牌手机输入法明文上传隐私!官方:承认+发补丁》中,bilibili 知名科技 UP 主 epcdiy 讨论了一个漏洞和一个猜想:
漏洞:https://avd.aliyun.com/detail?id=AVD-2023-42579
- 事实一:三星输入法调用了一个搜狗提供的 HTTP API (
http://shouji.sogou.com/web_ime/mobile_pb.php)将用户输入上传 - 事实二:调用这个 API 时三星输入法使用的是 HTTP 明文传输,这可能导致传输过程中这些信息被邻近的第三方窃取
- 事实一:三星输入法调用了一个搜狗提供的 HTTP API (
- 猜想:输入法将用户的键盘输入内容主动提供给第三方用于定向广告
这两者其实没有直接的因果关系,因为这个漏洞不会是基于定向广告的目的而产生的:无论三星输入法上传用户输入时使用 HTTP 还是 HTTPS 服务器传输,最终服务器都可以接收到用户输入,并可能作进一步的利用(包括定向广告在内)。
那么三星输入法为什么会如此“堂而皇之”地将用户输入上传到这个 API?这个 API 到底是不是为了定向广告而实现的?本文会分析、讨论这一个问题。
获取情报
我们先根据已知信息在互联网上检索。
其他人的研究
https://web.archive.org/web/20231003104425/https://www.dadclab.com/archives/912.jiecao
这篇 2011 年的文章对搜狗输入法 Windows 版进行了抓包,表明搜狗输入法在当时也有上传用户输入的行为,其上传的是原始键盘输入,但上传的域名与前面所述的 API 不同。
一个极其相似的接口
在 GitHub 上搜索 http://shouji.sogou.com/web_ime/mobile_pb.php,发现一段 sogou_cloud_words.py 的 Python 2 代码中包含一个极其相似的 API URL http://shouji.sogou.com/web_ime/mobile.php。
通读代码,代码大意是调用搜狗的 API 根据用户输入获取候选词(也就是俗称的“云输入”)。 实际执行起来也是如此,尝试输入拼音 9 键和拼音 26 键,均可以从 API 返回的数据中取得候选词:
>>> get_cloud_words('yuanmengzhixing')
['缘梦之星', '圆梦之星']
>>> get_cloud_words('64426744543')
['你好世界', '你喊世界']如果您对此感兴趣,可以尝试用 这段代码,我已经在原始代码的基础上进行了一点调整,使其可在 Python 3 中执行。
值得注意的是,虽然响应数据没有做混淆和加密,但返回的中文字符串使用的是 Unicode 编码(UTF-16-LE)。虽然是明文数据,但其并非 ASCII 字符,又是 Unicode 编码的,在各种抓包工具的十六进制视图以及文本视图中可能不能正常显示出来,一叶障目。
我的猜测
我的猜测是:这个 API 可能是用于输入法的云输入法功能(在本地词库以外额外推荐若干个候选词;一般出现在候选词列表中,或者额外展示一个候选词)。mobile_pb.php 可能是 mobile.php 接口的变体,从某种私有二进制格式改为了 Protobuf 的格式。
其实到这里,结论已经呼之欲出,我已经懒得继续深究下去。但隔几天后想起来自己手上还真有一台吃灰了很久的三星的 Android 设备,上面有预装三星输入法,于是顺便折腾了一下。
抓包方法
HTTP 抓包
得益于上面的已知明文传输漏洞,我们只需要一台普通的 Android 设备,配置 HTTP 代理即可抓包到输入法发起的 HTTP 请求。
这里我使用的是 whistle 抓包,在电脑上启动 whistle,手机与电脑连接到同一个局域网,配置手机 Wi-Fi 的代理服务器为 whistle 的所在电脑的 IP 以及 whistle 的端口号。
解读请求和响应 Payload
Protobuf 是一种自解释的格式,在数据中包含了字段的索引和类型信息(但不像 JSON、XML 等数据结构,protobuf 编码的二进制数据不包含字段的名称)。因此,即使手上没有 .proto 结构定义文件,也可以通过 protoc --decode_raw 对 Protobuf 编码的二进制数据进行简单的字段分割。
具体的做法如下:
# Linux
protoc --decode_raw < your_binary_file.bin
# Windows
type your_binary_file.bin | protoc --decode_raw抓包结果
下面给出一些抓包结果。
拼音 26 键输入:元梦之星
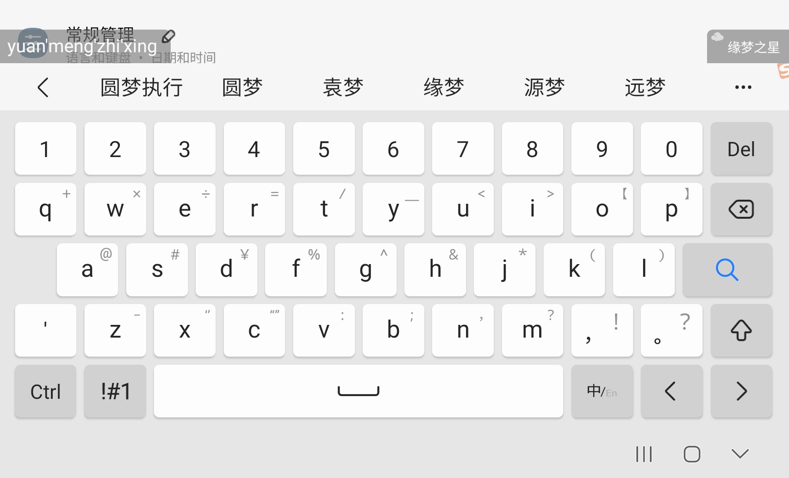
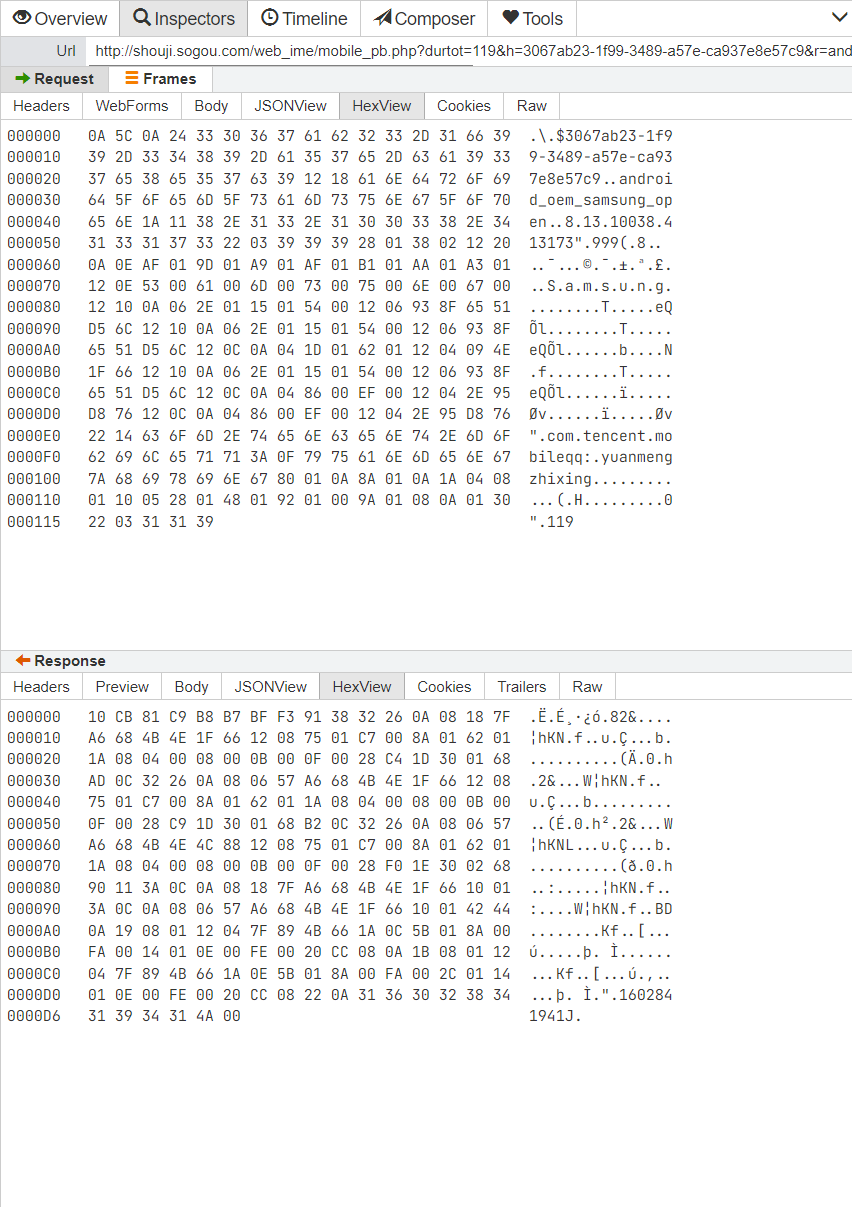
(最近这么热的词汇却不在首选位置?)
拼音 9 键输入:你好世界

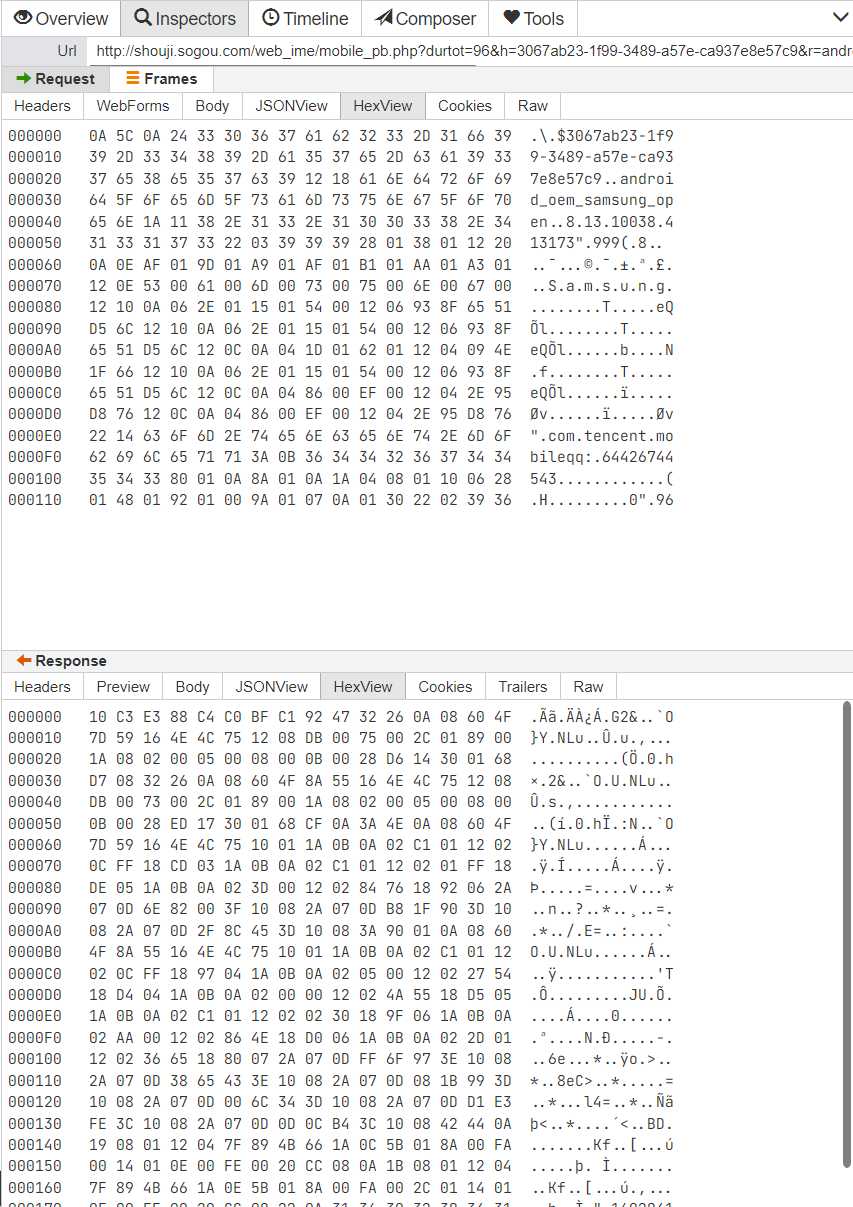
解析抓包结果
以 拼音 26 键输入:元梦之星 的抓包结果为例。
请求 body
使用 protoc 可以解析请求 body。其中包含当时的原始输入 yuanmengzhixing
$ protoc --decode_raw < yuanmengzhixing_req.hex
1 {
1: "3067ab23-1f99-3489-a57e-ca937e8e57c9"
2: "android_oem_samsung_open"
3: "8.13.10038.413173"
4: "999"
5: 1
7: 2
}
2 {
1: "\257\001\235\001\251\001\257\001\261\001\252\001\243\001"
2: "S\000a\000m\000s\000u\000n\000g\000"
}
2 {
1: ".\001\025\001T\000"
2: "\223\217eQ\325l"
}
2 {
1: ".\001\025\001T\000"
2: "\223\217eQ\325l"
}
2 {
1: "\035\001b\001"
2: "\tN\037f"
}
2 {
1: ".\001\025\001T\000"
2: "\223\217eQ\325l"
}
2 {
1: "\206\000\357\000"
2: ".\225\330v"
}
2 {
1: "\206\000\357\000"
2: ".\225\330v"
}
4: "com.tencent.mobileqq"
7: "yuanmengzhixing"
16: 10
17 {
3 {
1: 1
2: 5
}
5: 1
9: 1
}
18: ""
19 {
1: "0"
4: "119"
}响应 body
使用 protoc 可以解析响应 body。但暂时没有直接看到任何中文字符。
$ protoc --decode_raw < yuanmengzhixing_resp.hex
2: 4045303370227007691
6 {
1: "\030\177\246hKN\037f"
2: "u\001\307\000\212\001b\001"
3: "\004\000\010\000\013\000\017\000"
5: 3780
6: 1
13: 1581
}
6 {
1: "\006W\246hKN\037f"
2: "u\001\307\000\212\001b\001"
3: "\004\000\010\000\013\000\017\000"
5: 3785
6: 1
13: 1586
}
6 {
1: "\006W\246hKNL\210"
2: "u\001\307\000\212\001b\001"
3: "\004\000\010\000\013\000\017\000"
5: 3952
6: 2
13: 2192
}
7 {
1: "\030\177\246hKN\037f"
2: 1
}
7 {
1: "\006W\246hKN\037f"
2: 1
}
8 {
1 {
1: 1
2: "\177\211Kf"
3: "[\001\212\000\372\000\024\001\016\000\376\000"
4: 1100
}
1 {
1: 1
2: "\177\211Kf"
3: "[\001\212\000\372\000,\001\024\001\016\000\376\000"
4: 1100
}
4: "1602841941"
}
9: ""首先 protoc 回显字符串时对非 ASCII 字符是使用 8 进制显示(形如 \123),再回忆起前面获取情报时我们得知另外一个 mobile.php API 的中文出参是 UTF-16 编码的。因此,我们可以尝试将其视为二进制数据(而不是明文字符串),再按照 UTF-16-LE 编码解读,可以发现响应中确实包含与输入相对应的候选词。
>>> b"\030\177\246hKN\037f".decode('utf-16-le')
'缘梦之星'一些事实与结论
触发调用这个接口的时机?
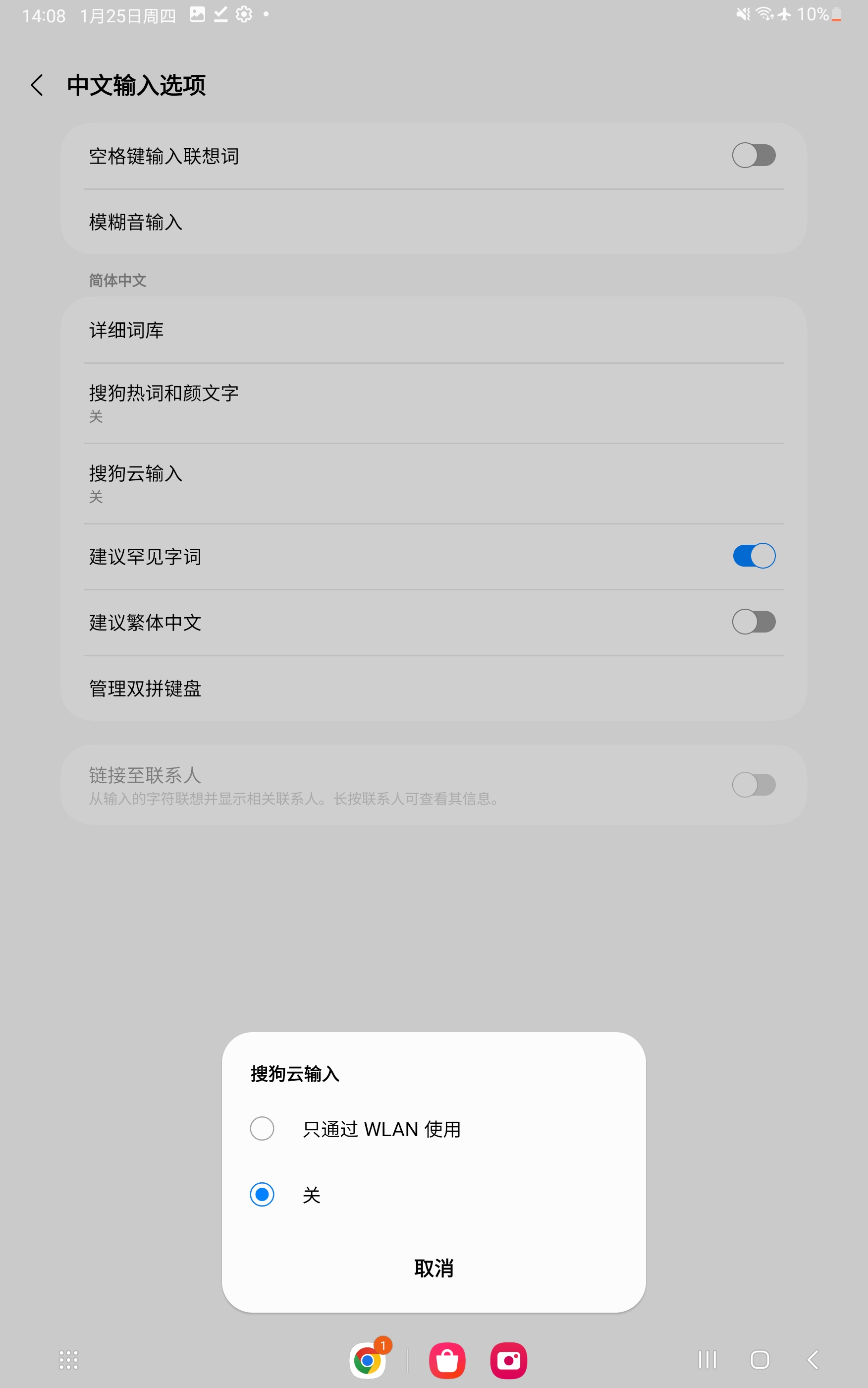
- 三星输入法仅在开启
中文输入法选项 - 搜狗云输入开关时,会将用户输入上传到mobile_pb.php这个 API,若关闭了这个开关,则不会请求这个 API。 - 当用户开启了
搜狗云输入,然后在键盘的拼音模式下键入时,输入法可能会调用前述接口,将当前未上屏的用户输入上传。
视频中没有提到的
- 当用户首次开启
中文输入法选项 - 搜狗云输入开关时,会要求用户同意一个第三方访问声明。这个第三方访问声明表明,用户使用云输入法功能时,需要收集用户的设备标识符(Android ID、OAID 等)。 搜狗云输入开关默认是关闭状态。

这个接口的功能?
- 这个接口可以接收拼音 9 键或拼音 26 键输入,输出与之匹配的候选词。
是否有其他信息同时被上传
- 三星输入法向这个接口传入的是用户的原始输入,不是用户实际上屏的词语,也不是用户实际上屏的词语的拼音。比如我在拼音 9 键输入法键入
64426744543,然后选择了你好世界这个候选词;最终仅64426744543这个输入被上传,而上屏的词语你好世界没有被上传。 - 请求的 query string 中的
h字段,以及请求 body 中包含一个引人注意的 UUID,这个 UUID 每次请求是相同的,有可能是设备标识符。 - 请求 body 中包含一个固定字符串
com.tencent.mobileqq,抓包之前我以为是输入框所在的 APP 的包名,但后来发现始终是固定值,这比较奇怪。
综上所述,这个接口的主要用途可能是“搜狗云输入”?但不排除该接口同时有其他用途或其他信息上传。
如果我是广告主?
如果我是广告主,我要被输入法的这个操作气晕,放着用户最终打出的词不用,反而收集用户的原始输入(血压上来了😤)。尤其是拼音 9 键的输入,重码(一个输入对应多个可能的字词)的可能性比拼音 26 键高得多。
总的来说?
- 某品牌手机输入法明文上传隐私?——用户的键盘输入确实是隐私,明文 HTTP 上传是事实存在的。
- 某品牌手机输入法上传用户输入用于定向广告?——我认为是有嫌疑的。目前我们只抓包分析了一类 HTTP 请求,并没有排除输入法通过其他途径上传用户输入数据的可能。要证实或证伪这个问题,并不容易做到。
以上内容仅代表个人观点。欢迎讨论。
iOS 原生输入法应该好很多
挺两难的,没有云词库的输入法是真的不好用…
个人隐私真是越来越不值钱~
今天这个输入法更新了,我刚才打开它的时候,给了两个选项,一个是上传数据的模式,一个是本地模式,这么看来似乎也不用大家再去扣代码确认了 ……
这是好事,不过也有人并不信任输入法提供的本地模式,会使用开源软件作为替代品。之前看到有博主介绍过一个叫 fcitx5-android 的开源 Android 输入法 APP。
小企鹅输入法吧,不在乎云词库的话可用性还是可以的,还有个同文输入法